
Feature Selection with D-Wave's Constrained Quadratic Model: A Straightforward Guide
In this guide, we'll delve into how D-Wave's Constrained Quadratic Model (CQM) can be effectively used for feature selection in machine learning.

This approach utilizes the unique capabilities of quantum annealers from D-Wave to handle complex optimization problems, offering a novel way to identify key features in a dataset for machine learning.
Creating a Virtual Environment
When working with Python, it’s common practice to manage dependencies through virtual environments. This helps maintain a clean workspace by isolating dependencies and package versions specific to each project. Think of it as organizing your toolkit for each project you work on.
Installing the Ocean SDK
The Ocean SDK is a collection of tools and libraries provided by D-Wave for interacting with their quantum systems. It's a critical component for anyone looking to leverage D-Wave's quantum computing capabilities.
Installation Steps
To install the Ocean SDK, run this command in your terminal:
pip install dwave-ocean-sdk && dwave setupFollow the setup script which will guide you through:
Accepting the terms and conditions,
Creating a configuration file,
Entering your API token (found on the Leap Dashboard here),
And specifying your Solver API Endpoint (also available on the Leap Dashboard).
Test your setup by running dwave ping to confirm connectivity to the D-Wave system.
Implementing the Feature Selection Code
# Importing Necessary Libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from dwave.plugins.sklearn import SelectFromQuadraticModelThis code imports the necessary libraries. pandas is used for data manipulation, train_test_split from sklearn for dividing our dataset, and SelectFromQuadraticModel from D-Wave's library for feature selection.
# Loading the Dataset
df = pd.read_csv('yourdataset.csv')
X = df.drop(['target'], axis="columns")
y = df['target']Here, we load a dataset. The features (X) and the target variable (y) are defined as well.
# Splitting the Dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)We split the dataset into training and testing sets, ensuring we have separate data for training the model and evaluating its performance.
# Defining the Number of Features to be Selected
n_features = 10We specify the number of features we aim to select (in this case, 10).
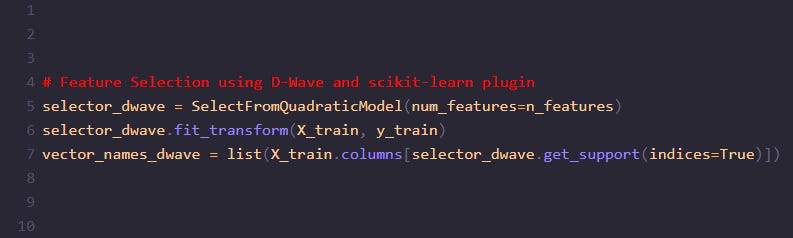
# Feature Selection Using D-Wave
selector_dwave = SelectFromQuadraticModel(num_features=n_features)selector_dwave.fit_transform(X_train, y_train)
vector_names_dwave = list(X_train.columns[selector_dwave.get_support(indices=True)]D-Wave's SelectFromQuadraticModel is used to select the specified number of features based on the training data.
# Creating New Datasets with the Selected Features
X_train_dwave = X_train[vector_names_dwave]
X_test_dwave = X_test[vector_names_dwave]We create new training and testing datasets using the features selected by the D-Wave model.
# Displaying Selected Features
print("Selected Features using D-Wave's Constrained Quadratic Model:")
for feature in vector_names_dwave:
print(feature)Finally, we display the features selected by the D-Wave model, providing insight into which variables the model deems most significant.